Как удалить страницу сайта из результатов выдачи

Содержание:
- Почему страницу стоит удалить из индекса
- Какие страницы нужно удалять из выдачи?
- Методы удаления страницы
- Страница отдает код ответа 404
- Запрещаем обход страницы поисковым роботам в файле robot.txt
- Запрещаем обход сайта в мета-данных в коде сайта
- Настраиваем 301 редирект на нужную страницу
- Самостоятельное удаление страницы из панели Яндекс.Вебмастера
- Самостоятельное удаление страницы из панели Google Search Console
- Итоги
Контент должным быть ценным для аудитории, а страницы – доступными роботу для сканирования. Но бывают ситуации, когда индексация отдельных страниц не нужна, способствует сокращению эффекта от продвижения. О том, когда именно стоит удалить страницу сайта из выдачи поисковых систем, и каким образом это сделать, поговорим далее.
Почему страницу стоит удалить из индекса
Владелец ресурса желает, чтобы будущий клиент обнаруживал его веб-ресурс в выдаче. Поисковики же хотят, чтобы человек получил полезные и релевантные сведения. А потому для индексации доступны должны быть только те страницы, что будут выводиться в результаты поиска.
Есть несколько причин выполнить запрет на индексацию тех или иных частей сайта. Первый для этого повод – когда контент не имеет должных смыслов для поиска и потенциальных клиентов, либо и вовсе содержит неверные сведения. Например, это административные или особые технические страницы, а также данные с конфиденциальной информацией. Отдельные страницы формируют иллюзию дублированной информации, что тоже нарушает правила поисковиков. Это приводит к штрафам для всего сайта.
Следующая причина – поисковой бюджет используется нерационально. В такой бюджет входит некоторое число страниц, что может просканировать поисковая система. В интересах владельца сайта траты должны уходить только на ценные и эффективные страницы. Для получения быстрой и качественной индексации важных данных, требуется ограничить нежелательный контент от сканирования.
Смена URL-адреса страницы – это еще один повод, из-за которого вы должны ограничить к ней доступ. В выдаче отображаются ссылки на несуществующие страницы при внесении изменений в URL-адрес. Это возникает, например, при редактуре домена. Нередко затруднение возникает при изменении отдельного раздела. Например, робот обходит страницу и включает ее в выдачу. После этого вы меняете URL страницы, но поисковик показывает старый адрес. В этой ситуации выполните 301 редирект со старого адреса на новый. Параметры старого адреса будут переданы, а позиция останется в выдаче.
Наконец, последняя ситуация – это обычная ликвидация страницы. Все изображения, тексты и иные вложения сохраняются в индексе поисковиков. При этом URL на удаленную страницу будет пребывать в выдаче длительное время. Чтобы не допустить этого, просто ограничьте доступ робота к ней.
Какие страницы нужно удалять из выдачи?
Некоторые страницы вашего сайта следует убрать из индекса. Вот что сюда входит:
- Копии сайта. При настройке таких страниц укажите зеркало, используя 301 редиректы, либо атрибут rel="canonical". Так вы оставите оценку сайта и укажите роботу, где находится первоисточник, а где его аналог. Ограничивать ресурс от индексации не стоит. Так вы ликвидируете заработанную репутацию и данные о возрасте.
- Страницы печати. Это ценные для аудитории страницы, поскольку дают возможность изучить сведения в качестве особого формата текста. Однако является такая страница копией основной. Если она доступна для сканирования, робот посчитает ее приоритетной. А потому лучше ограничьте поисковикам доступ к ней.
- Ненужные документы. Это файлы формата DOC, PDF, YML и т.д. Скорее всего, содержимое подобных документов не отвечает потребностям ваших пользователей. Защитите их от изучения роботом в robots.txt или выставите запрет на индексацию.
- Разрабатываемые страницы.
- Технические данные. Такие страницы используются только служебным администратором. Это блок авторизации для получения доступа к управлению сайтом.
- Конфиденциальные сведения об аудитории. Тут содержатся не только имена и фамилии, но и сведения по платежам, которые клиенты оставляют во время оформления заказа. Все они находятся под надежной защитой от изучения.
- Элементы пользователей и форматы. Это страницы, полезные клиентам, но не несущие особой ценности как информация. Сюда входят формы авторизации, корзина, персональный кабинет и обработка заявок. Постарайтесь ограничить к ним доступ робота.
- Страницы пагинации. Они не полностью повторяют структуру главной страницы. Вы можете закрыть их от индексации, либо выполнить настройку атрибутов rel="canonical", rel="prev" и rel="next". Укажите в Google Search Console, а именно в блоке «Параметры URL», какие именно данные разбивают страницы.
- Страницы сортировки. Из-за своего содержания подобные страницы с хожи друг на другом. Для снижения риска получения санкций от Яндекс и Google, закройте к ним доступ.
Получается, к каждой странице требуется особый, индивидуальный подход. Большинство же страниц требует ограничения к ним прохождения поисковых роботов. О том, как удалить страницу из поисковой выдачи Яндекс и Google, подробно расскажем далее.
Методы удаления страницы
Есть несколько методов ликвидации страницы из поиска. Разберем все варианты по отдельности.
Страница отдает код ответа 404
Самый простой в исполнении метод. Однако продолжительность удаления информации из выдачи может занять до одного месяца. Вы удаляете страницу как из поисковиков, так и с сайта.
Удаление страницы происходит в административной панели сайта. Вы обеспечиваете http-статус с кодом 404 not found для конкретного URL. При повторном посещении робота, сервер сообщит ему об отсутствии документа. Робот поймет, что страница больше не доступна и удалит ее из выдачи. Этот метод включает несколько особенностей:
- Страница исчезает из сайта, поэтому если вы хотите всего лишь скрыть конфиденциальные данные, то лучше обратитесь к другим методам.
- Настройка проводится всего в пару кликов.
- Если на страницу поступают входящие ссылки, то выгоднее настроить 301 редирект.
- К выпадению страницы из поиска приводит не удаление ее с сайта, а дальнейшая индексация. А потому удаление займет от одного дня до месяца.
Для пользователя переход на удаленную страницу будет выглядеть как «Ошибка 404». Такие страницы можно креативно оформить, чтобы клиент не «потерялся», а продолжил изучение сайта. Это напрямую сказывается на конверсии вашего ресурса.
Запрещаем обход страницы поисковым роботам в файле robot.txt
Используя этот метод, вы не удалите страницу из поиска, а только скроете ее из органической выдачи. Сама страница останется доступной для просмотра из иных каналов трафика.
Использование robots.txt – это довольно популярный способ расстаться с отдельными разделами и объектами. Используя этот файл, вы разрешаете и запрещаете индексацию. Для запрета нужно использовать директиву Disallow – но только в том случае, если у вас есть доступ к корневой папке домена. В ином случае придется использовать мета-теги.
Содержание robots.txt включает две строчки:
- User-agent. Это название робота, в отношении которого используется запрет. Название можно брать из базы данных сканеров. Если вы хотите закрыть страницу от всех, то пропишите «User-agent: *».
- Disallow. Укажите адрес, о котором идет речь.
При необходимости в одной файле можно запретить несколько объектов одного сайта, которые будут независимы друг от друга.
Для поисковиков действие в robots.txt – всего лишь рекомендация. Даже при выполнении этого указания ресурс по-прежнему останется в выдаче, но уже с надписью о закрытии через файл.
Запрещаем обход сайта в мета-данных в коде сайта
Работа ведется в html-коде среди тегов head:
Введите команду и дождитесь очередной индексации, после которой изменения вступят в силу. Используя этот метод, вы можете удалить страницу из одного поисковика и оставить его в других. Рекомендуется использовать редактирование мета-данных, если вам нужно убрать страницу из индекса, но оставить информацию в ней для внутреннего пользования.
Такой метод не подходит для сайтов, выполненных на WordPress. Вопрос решается посредством установки плагина Yoast SEO, где каждая страница закрывается отдельным мета-тегом.
Настраиваем 301 редирект на нужную страницу
Контент страницы перестанет быть доступным для всех посетителей, включая владельцев сайта. Суть метода проста: пользователь ищет страницу, которой больше нет, но сайт направляет его по другому адресу.
Настраивается редирект разными способами. Тут все зависит от CMS, на которой выстроен и работает ваш сайт. Сам метод используется при необходимости обработать большое число устаревших страниц или при полной смене структуры сайта. Редирект помогает оставить позиции в рейтингах поисковиков, благодаря чему усилия по оптимизации сайта не обнулятся. Переадресация в поисковиках займет 1-3 дня – все зависит от вашего сайта.
Самостоятельное удаление страницы из панели Яндекс.Вебмастера
В Вебмастере присутствует функция «Удалить URL», с помощью которого вы способны ликвидировать страницы из поиска. Но для начала обеспечьте выполнение следующих действий:
- Настройте ответ сервера с несуществующих страниц «404 – не найдена», «410 – удален» и «403 – доступ запрещен».
- Закройте от индексации в robots.txt необходимые страницы или группы страниц. Вы также можете использовать мета-тег .
Далее переходим в раздел Вебмастера и вводим адреса страниц, подлежащие удалению. В день вы можете выполнить до 500 удалений страниц из индекса Яндекса. Вы можете удалять группы страниц – например, весь блог или каталог, а иногда и все страницы сайта сразу. Для этого кликните кнопку «По префиксу»:
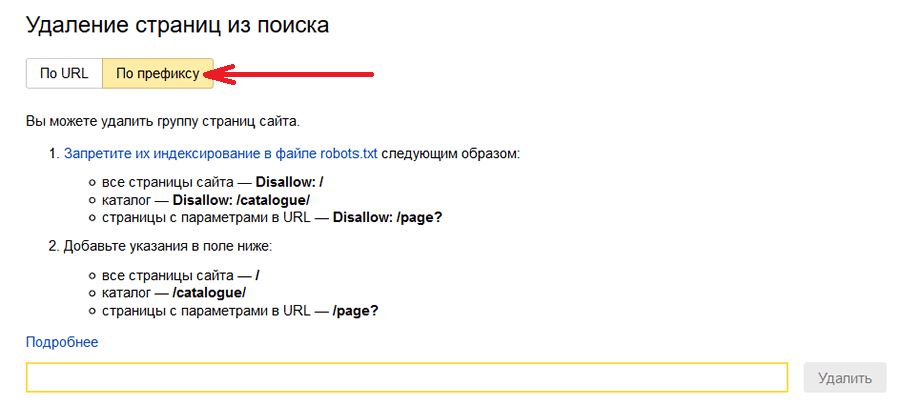
Лимит на день – 20 префиксов. Смотреть статус удаляемых страниц можно здесь:
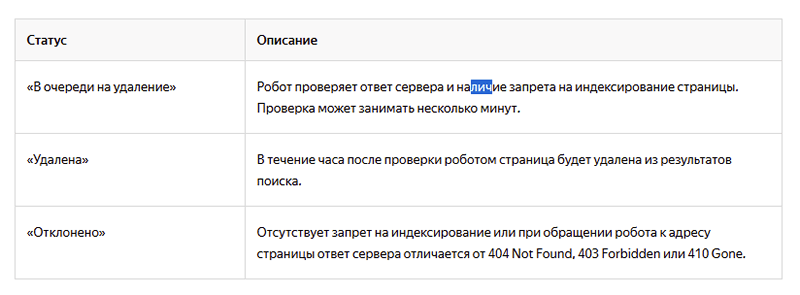
При очередном «исследовании» робот Яндекса обратится к файлу robots.txt, а только потом к страницам. Целостный обход займет значительное время, а потому настройке robots.txt уделите особое внимание.
Самостоятельное удаление страницы из панели Google Search Console
У Google есть такой же инструмент, как и у Яндекса – «Удалить URL».

Вы блокируете страницы сроком до 90 дней, а затем они снова демонстрируются в выдаче. Кликните по кнопке «Временно скрыть». Появится окно, в котором забейте адрес страницы, подлежащей удалению.
- Адрес страницы принадлежит сайту в Search Console.
- Анкорные ссылки типа #link убираются из URL.
- Из поиска исчезают все типы страницы с протоколом http и https, а также URL с префиксом www и без него.
- Если страница имеет дубли, то ее нужно отправить дополнительные запросы со всеми их адресами.
Гугл предлагает выбрать из трех вариантов:

При ликвидации URL из кэша и временного исключения из поиска, страница, вместе с кэшированной копией, ликвидируется из выдачи продолжительностью до 90 дней. Вариант «удалить исключительно из кэша» подразумевает наличие страницы в выдаче, но ликвидацию сохраненной копии. Наконец, способ «очистка кэша и скрытие на время всех URL...» поможет удалить все страницы и копии, которые начинаются с прописанного префикса. Если вы желаете убрать сайт целиком,то не прописывайте никакого пути, а поле сохраните пустым.
О том, как быстро удалить страницу из поисковый выдачи навсегда, Google тоже позаботился. Сделайте следующее:
- Ликвидируйте весь контент и постарайтесь убедиться, что выдается ответ сервера 404 или 410.
- Установите запрет на индексирование метатегом .
- Установите блок на доступ к контенту - допустим, поставьте пароль.
Применять метатег, а не запрет в самом файле robots.txt требуется, поскольку сам файл является лишь рекомендацией для Гугл.
Итоги
Процедура ликвидации неактуальных сведений из поисковиков имеет следующие характерные особенности:
- Можно выполнить ответ сервера.
- Можно использовать сервисы вебмастеров Яндекса и Гугл.
- Допускается ограничить от индексации требуемые для ликвидации страницы.
В Google присутствует возможность убрать сохраненные копии страницы, а у Яндекса подобная функция отсутствует: копии хранятся здесь долгое время. Если у Гугл восприятие robots.txt не в приоритете, то у Яндекса наоборот. Помните об этих отличиях при работе со страницами сайта.
А что вы думаете по этому поводу? Давайте обсудим в комментариях!





