Системный интернет-маркетинг
для кратного роста бизнеса

Как мы работаем
Работы по интернет-маркетингу в компании СЕО-Импульс открыты и измеримы для заказчика: еженедельные срезы, доступная аналитика по трафику, заявкам и продажам. Мы подбираем эффективные маркетинговые инструменты для вашего бизнеса. Контролируем ДРР по каждому каналу рекламы. Схема работы нашей работы указана ниже.
-
SWOT-анализМаркетинговая разработка продукта. Выбираем стратегию для кратного роста прибыли. Подключение систем сквозной аналитики.
-
Уровень MVPАнализ воронок продаж на всех этапах. Тестируем продукт перед запуском маркетинговых работ. Находим "точки выхода" аудитории. Модернизируем продукт.
-
Регистрация вНаша стратегия становится прозрачной и измеримой для заказчика услуги. Все этапы работы переносятся в собственную CRM.
 -системе, формирование задач
-системе, формирование задач -
СтратегияИндивидуальный пакет работ в рамках стандартов компании. Творчество в технических рамках. Приоритизация задач, работа недельными итерациями.
-
ВнедрениеСамостоятельно или через тех. поддержку клиента внедряем доработки. Выполняем комплекс работ по модернизации продуктов клиента.
-
Оценка эффективностиАнализ маркетинговых данных. Используем инструменты Яндекс.Метрики, Google Analytics, Roistat и Calltouch. Еженедельная аналитика соответствия по KPI.
-
Цикл интернет-маркетингаРабота по замкнутому циклу: оценка эффективности гипотезы - поиск точек роста - постановка задач - внедрение и тестинг - оценки эффектиности.
-
Проблемные каналыНаходим убыточные каналы трафика и перераспределяем бюджет в прибыльные направления. Контроль ДДР для всех каналов трафика.
-
Масштабирование успехаУвеличиваем вложения в прибыльные каналы рекламы. Расширяем поток целевой аудитории, которая показывают самую высокую эффективность для бизнеса.
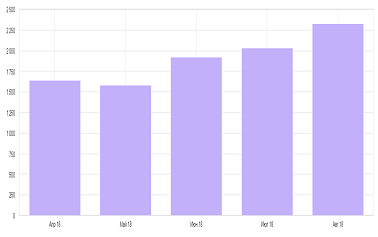
- Результат продвижения в Яндексе
Сайт: lesangar.ru
Регион: Москва и Московская область
Запрос Позиция планкен из лиственницы 5 палубная доска 7 террасная доска из лиственницы 8 вагонка из лиственницы 6 половая доска из лиственницы 3 имитация бруса 10 - Результат продвижения в Яндексе
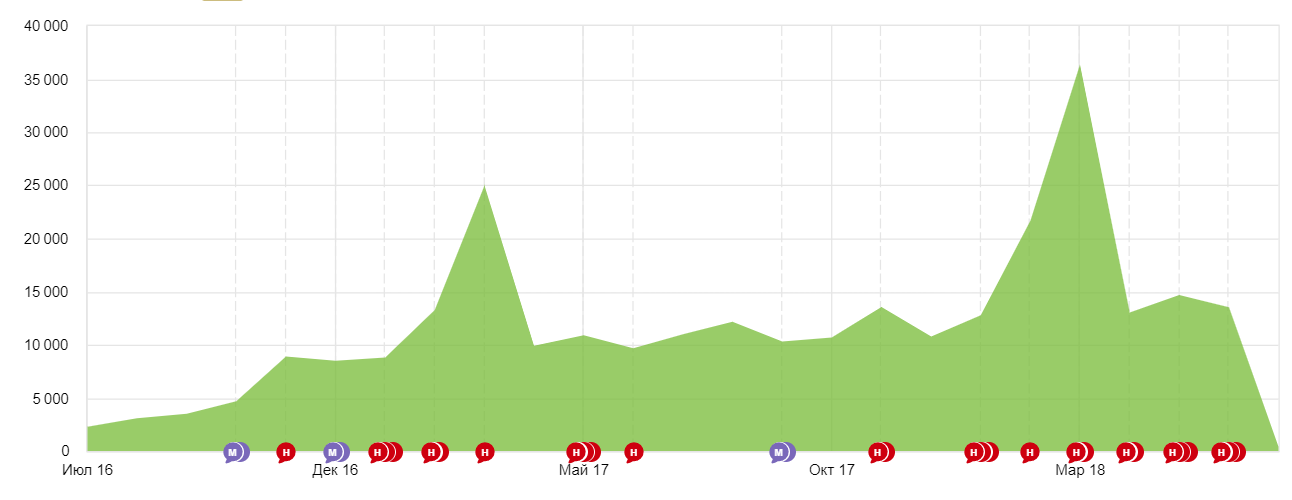
Сайт: http://www.vipservicemarket.ru/
Регион: Москва
Запрос Позиция доставка воды 3
вода в офис 4 доставка воды на дом 4 купить воду 1 заказ воды 3 - Результат продвижения в Яндексе
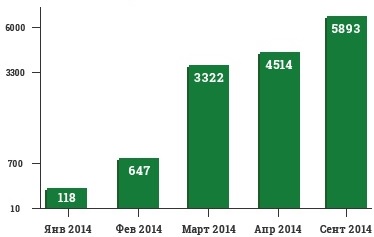
Сайт: mosmedpatronage.ru
Регион: Москва и Московская область
Фраза Яндекс Google сиделка на час 4 3 сиделка в больницу 10 4 сиделка для пожилого человека 20 6 патронажная служба 12 7 сиделка для лежачего больного 13 6 - Результат продвижения в Яндексе
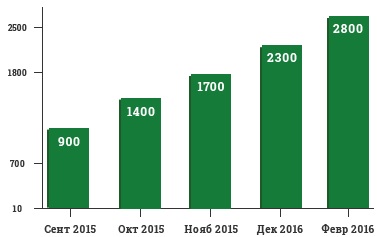
Сайт: zavodstekol.ru
Регион: Москва и Московская область
Фраза Яндекс Google стекло цветное 2 16 фотопечать на стекле 2 56 стекло оптивайт 2 26 гнутое стекло 3 8 закалка стекла 3 31 - Результат продвижения в Яндексе
Сайт: http://www.vipservicemarket.ru/
Регион: Москва
Запрос Позиция доставка воды 3
вода в офис 4 доставка воды на дом 4 купить воду 1 заказ воды 3 - Результат продвижения в Яндексе
Сайт: posadsb.ru
Регион: Московская область
Запрос Позиция охрана пушкино 5
охрана сергиев посад 3 охрана павловский посад 5 охрана щелково 3 охрана мытищи 4 охрана ногинск 2 - Результат продвижения в Яндексе
Сайт: florist-express.ru
Регион: Московская область и 50+ регионов России
Запрос Позиция доставка цветов зеленоград 7
доставка цветов химки 4 доставка цветов сергиев посад 6 цветы красногорск 6 доставка цветов лазаревское 8 доставка цветов алушта 6 - Результат продвижения в Яндексе
Сайт: http://archishow.ru/
Регион: Москва
Запрос Позиция организация детских праздников 4 проведение детских праздников 2 агенство детских праздников 2 аниматоры на день рождения 3 детские аниматоры 5 шоу для детей 2 заказать аниматора 4 - Результат продвижения в Яндексе
Регион: Москва
Запрос Позиция грузовые автомобили хендай 2 грузовые автомобили isuzu 3 купить фотон грузовик 3 купить foton грузовик 3 hyundai грузовик 2 купить грузовик исузу 3 купить исузу 3 - Результат продвижения в Яндексе
Сайт: palikha-clinic.ru
Регион: Москва и Московская область
Фраза Яндекс Google барокамера в москве цена сеанса 2 3 баротерапия цена 3 2 лечение межпозвонковой грыжи без операции 6 28 лечение грыжи позвоночника без операции 9 48 смт терапия 5 49
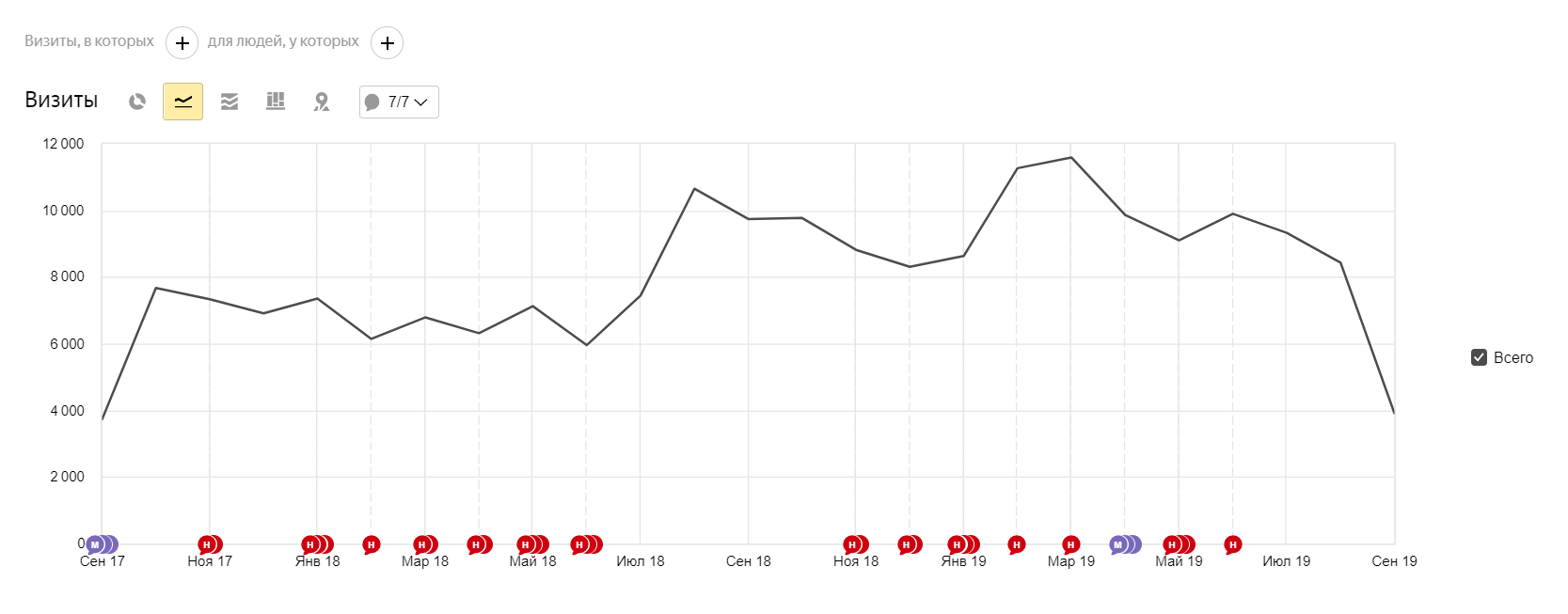
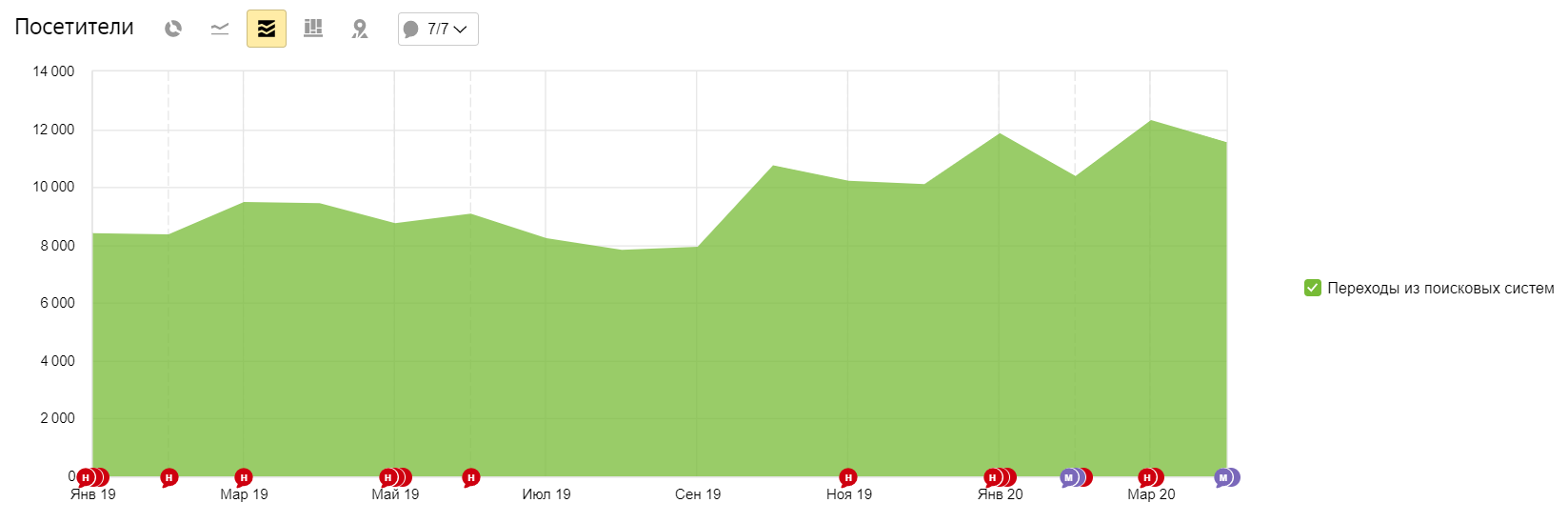

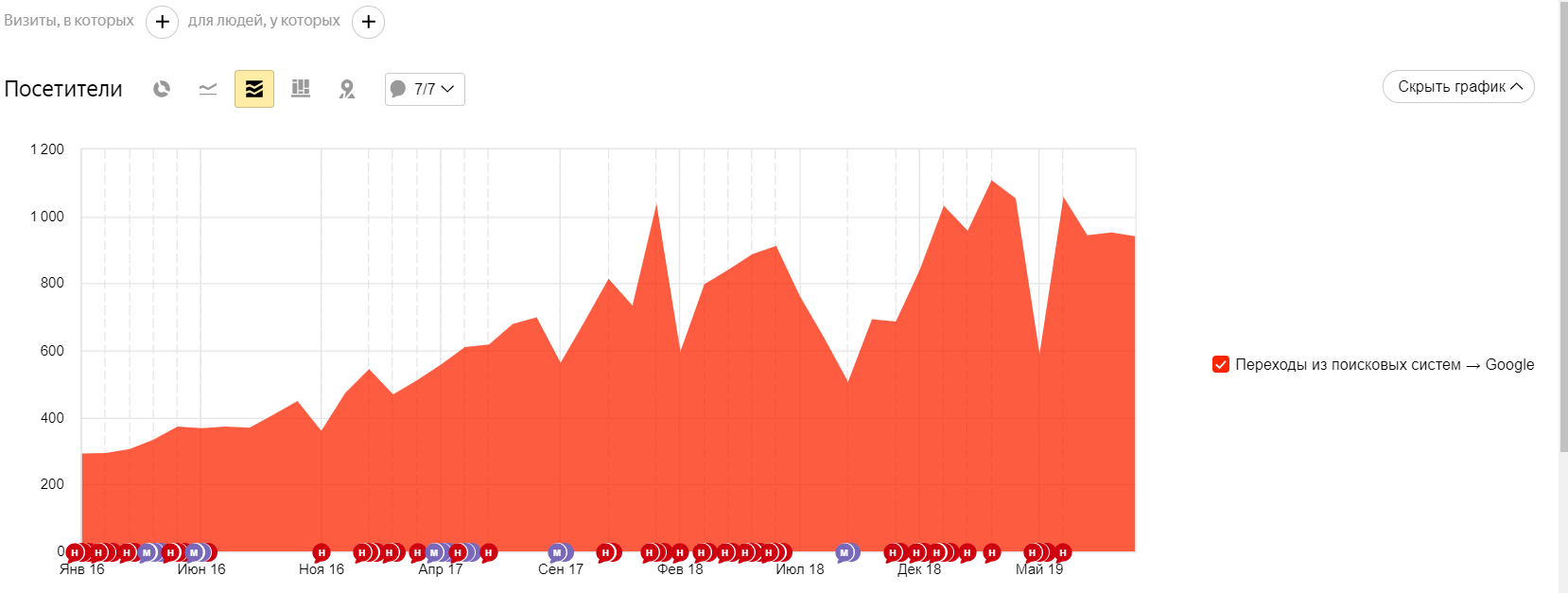
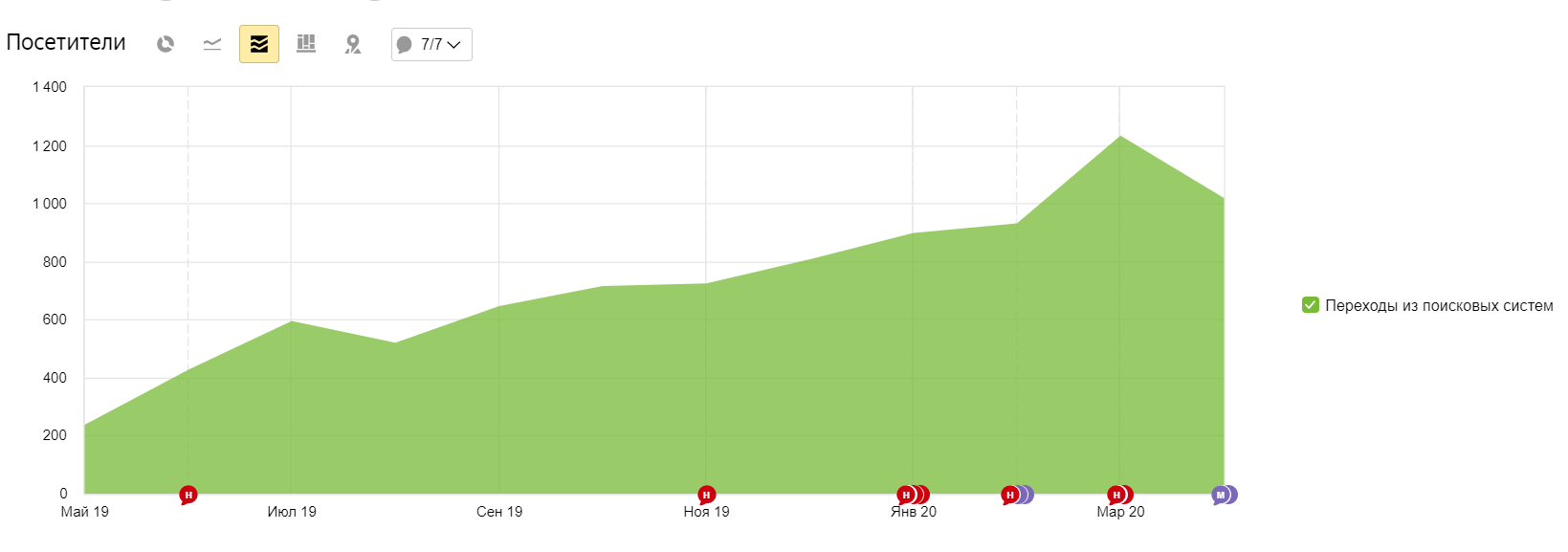


-
 Роман Щербаков (Фонд Сколково)Директор департамента по маркетингу и связям с общественностьюБлагодарим компанию "СЕО-Импульс" за проведенный аудит юзабилити нашего основного домена и его поддоменов. Целью данной работы было получить независимую профессиональную оценку удобства использования различных элементов на сайте. С работой команда справилась на "отлично". По итогам аудита мы получили развернутый отчет с указанием предложений по изменениям на сайте, а также мы получили более 20 видеозаписей с тем, как фокус-группа выполняла те или иные задачи на сайте с мобильных устройств и ПК. Рекомендуем компанию СЕО-Импульс как надежного и профессионального подрядчика.
Роман Щербаков (Фонд Сколково)Директор департамента по маркетингу и связям с общественностьюБлагодарим компанию "СЕО-Импульс" за проведенный аудит юзабилити нашего основного домена и его поддоменов. Целью данной работы было получить независимую профессиональную оценку удобства использования различных элементов на сайте. С работой команда справилась на "отлично". По итогам аудита мы получили развернутый отчет с указанием предложений по изменениям на сайте, а также мы получили более 20 видеозаписей с тем, как фокус-группа выполняла те или иные задачи на сайте с мобильных устройств и ПК. Рекомендуем компанию СЕО-Импульс как надежного и профессионального подрядчика. -
 Ким Ю.С.Генеральный директорВыражаем благодарность компании "СЕО-Импульс" за эффективное продвижение нашего сайта cuckoo.ru в поисковых системах Яндекс и Google. На протяжении более чем 6 лет сотрудники компании "СЕО-Импульс" зарекомендовали себя, как надежные и высококвалифицированные профессионалы в своей области.
Ким Ю.С.Генеральный директорВыражаем благодарность компании "СЕО-Импульс" за эффективное продвижение нашего сайта cuckoo.ru в поисковых системах Яндекс и Google. На протяжении более чем 6 лет сотрудники компании "СЕО-Импульс" зарекомендовали себя, как надежные и высококвалифицированные профессионалы в своей области. -
 Сергей БрусковГенеральный директор Диам-АлмазОт лица ООО “Диам-Алмаз” выражаю благодарность нашим давним партнерам компании “СЕО-Импульс” и конкретно Алексею Бузину, за продвижение и сео оптимизацию нашего сайта www.diam-almaz.ru.
Сергей БрусковГенеральный директор Диам-АлмазОт лица ООО “Диам-Алмаз” выражаю благодарность нашим давним партнерам компании “СЕО-Импульс” и конкретно Алексею Бузину, за продвижение и сео оптимизацию нашего сайта www.diam-almaz.ru.
Профессионализм и постоянное совершенствование результата этой компании заслуживают уважения! Рекомендую их как надежного партнера по раскрутке сайтов!
-
 Артур АкопянГенеральный директорКомпанию подсказали знакомые. За 3 месяца мой сайт благодаря работам по seo продвижению и оптимизации вышел в ТОП-10 Яндекс/Google по основным ключевым фразам.
Артур АкопянГенеральный директорКомпанию подсказали знакомые. За 3 месяца мой сайт благодаря работам по seo продвижению и оптимизации вышел в ТОП-10 Яндекс/Google по основным ключевым фразам.
Этот невероятный факт - результат ответственной работы СЕО-Импульс. Благодарю Алексея Бузина и всю его команду за профессионализм и развитие моего бизнеса!
-
 Ирина ВальтфогельРуководитель КИД-праздникРаботу с компанией начали в рамках seo-продвижения нашего сайта kid-prazdnik.ru. С первых месяцев работы мы увидели результат по трафику из поисковых систем. За первый год работы мы расширили наше семантическое ядро до 300 запросов, по большинству из которых мы занимаем ТОП-10. Совместно с СЕО-Импульс запустили рекламу в Яндексе, Вконтакте и Фейсбуке. Неоднократно встречались с Руководителем отдела по SEO, где совместно принимали решения о дальнейшей стратегии развития компании. Очень довольны сотрудничеством с компанией СЕО-Импульс.
Ирина ВальтфогельРуководитель КИД-праздникРаботу с компанией начали в рамках seo-продвижения нашего сайта kid-prazdnik.ru. С первых месяцев работы мы увидели результат по трафику из поисковых систем. За первый год работы мы расширили наше семантическое ядро до 300 запросов, по большинству из которых мы занимаем ТОП-10. Совместно с СЕО-Импульс запустили рекламу в Яндексе, Вконтакте и Фейсбуке. Неоднократно встречались с Руководителем отдела по SEO, где совместно принимали решения о дальнейшей стратегии развития компании. Очень довольны сотрудничеством с компанией СЕО-Импульс. -
 А.В. Мартыновген.директор ЗАО "Уни-Пак"Хотим выразить благодарность агентству "СЕО-Импульс" за качественно проделанную работу. По итогам более чем 4-х месячного сотрудничества в рамках seo-продвижения, доработки сайта и контекстной рекламы в Яндекс Директ можем смело порекомендовать данное агенство как компетентного и ответственного подрядчика, знающего свое дело!
А.В. Мартыновген.директор ЗАО "Уни-Пак"Хотим выразить благодарность агентству "СЕО-Импульс" за качественно проделанную работу. По итогам более чем 4-х месячного сотрудничества в рамках seo-продвижения, доработки сайта и контекстной рекламы в Яндекс Директ можем смело порекомендовать данное агенство как компетентного и ответственного подрядчика, знающего свое дело! -
 ИнессаРуководитель АН «БЕСТ-Элит»Выражаем благодарность за помощь в создании и настройке кампании в сети контекстной рекламы Яндекс Директ.
ИнессаРуководитель АН «БЕСТ-Элит»Выражаем благодарность за помощь в создании и настройке кампании в сети контекстной рекламы Яндекс Директ.
Благодаря грамотно проработанной стратегии и профессионализму СЕО-Импульс нам удалось получить множество клиентов на аренду недвижимости.
-
 И.С. ШуршалевЗам. Генерального директора КОМСЕТ-СервисООО "КОМСЕТ-Сервис" выражает благодарность ООО "СЕО-Импульс" за успешное и продуктивное сотрудничество в части SEO продвижения основного сайта нашей компании в сети Интернет. Компания "СЕО-Импульс" выполняет взятые на себя обязательства по продвижению сайта и его оптимизации. Отдельно хочется отметить высокий профессионализм сотрудников и способность оперативно решать поставленные задачи ( Ведущий аккаунт-менеджер Елизавета). Надеемся на долгосрочное сотрудничество, а также рекомендуем Вас в качестве достойного и ответственного партнера.
И.С. ШуршалевЗам. Генерального директора КОМСЕТ-СервисООО "КОМСЕТ-Сервис" выражает благодарность ООО "СЕО-Импульс" за успешное и продуктивное сотрудничество в части SEO продвижения основного сайта нашей компании в сети Интернет. Компания "СЕО-Импульс" выполняет взятые на себя обязательства по продвижению сайта и его оптимизации. Отдельно хочется отметить высокий профессионализм сотрудников и способность оперативно решать поставленные задачи ( Ведущий аккаунт-менеджер Елизавета). Надеемся на долгосрочное сотрудничество, а также рекомендуем Вас в качестве достойного и ответственного партнера. -
 СМИРНОВ Д.В.Генеральный директор ООО “Релив”Компания ООО «СЕО-Импульс» ещё в 2013 году разработала нам новый сайт с адаптивным дизайном.
СМИРНОВ Д.В.Генеральный директор ООО “Релив”Компания ООО «СЕО-Импульс» ещё в 2013 году разработала нам новый сайт с адаптивным дизайном.
Также мы уже несколько лет сотрудничаем по продвижению сайта.
Результатами проделанной работы довольны, а самое главное, что результаты улучшаются каждый месяц!
Вопросы по работе с компанией СЕО-Импульс
После подготовим индивидуальное коммерческое предложение. Затем его можно будет обсудить при встрече у нас или у вас в офисе. При выборе нескольких маркетинговых каналов мы предоставляем существенную скидку до 15%.
Отвечая на поставленный вопрос, можно сказать так - если ваш продукт (чаще всего сайт) готов к продажам, то мы готовы приводить лиды на 5-ый рабочий день.
при оплате за 3 месяца
ОСТАЛОСЬ
-
Как продвинуть в топ строительную компаниюИстория успеха строительной компании в Московской области. Как за 3 года мы помогли построить свыше 200 малоэтажных объектов.
 VC.RU 11.07.2021
VC.RU 11.07.2021 -
13 ошибок, которые убивают конверсию вашего интернет-магазинаТоп ошибок, которые влияют на воронку продаж в e-commerce. 13 факторов, которые мешают вашему сайту эффективно продавать.
 29.04.2021
29.04.2021 -
Проблемы интернет-агентства при развитии клиентских сайтовКак команда "СЕО-Импульс" выполняла специфические задачи от частной охранной фирмы. Построение топонимической структуры.
 31.01.2021
31.01.2021 -
Кейс по продвижению компании РУС-ТеплицыКейс по продвижению компании-производителя теплиц и тепличного оборудования. С нуля до лидеров рынка за 2 года.
 VC.RU 01.10.2020
VC.RU 01.10.2020 -
Увеличение посещаемости с 5 до 150 человек в суткиПроведение технической оптимизации, подготовка сайта к продвижению.Приток целевого трафика с поисковых систем Яндекс и Google
 09.07.2020
09.07.2020










- Сертифицированный штат сотрудников
- Постоянные участники конференций: ECOM Expo, SEO Conference, All in top Conf
- Собственный образовательный центр - seo-school.ru
- Собственная CRM-система ведения проектов
- Более 10 лет на рынке, свыше 300 реализованных проектов







 Калькулятор
Калькулятор
